Architetture distribuite

L'architettura Client Server è un'architettura di rete nella quale genericamente un computer client o terminale si connette ad un server per usare un certo servizio. Il server è il dispositivo che condivide il servizio, mentre i client sono i dispositivi che utilizzano il suddetto servizio.
Un’applicazione di rete si individuano 3 strati principali:

Ogni strato può essere suddiviso in altri sottostrati, e si parla di architetture N-tier:
Architettura N-Tier
Una architettura N-Tier è una architettura Client Server dove per motivi di prestazioni e di sicurezza i vari server si suddividono i vari ruoli di generazione delle viste, elaborazione dei dati, archiviazione dei dati.Più aumenta il numero di Tier (Livelli) più i dati sono sicuri, ma la lettura dei dati è più lenta perché deve passare per più macchine. Nell'architettura N-Tier si individuano possono individuare i seguenti livelli (alcuni, poi possono essere implosi in un unico livello):
- Presentation Tier : si occupa di realizzare l'interfaccia grafica e presentare i dati all'utente, spesso si avvale di applicativi in esecuzione sul client (per esempio codice Javascript per richieste in Ajax su un sito web o altre applicazioni stand-alone che comunicano con il server)
- Web Tier : si occupa di generare le pagine web dinamiche
- Business/Middleware Tier : si occupa di coordinare le applicazioni, i processi, effettuare calcoli e decisioni
- Data Access Tier : si occupa di gestire l'accesso al database, controllare che i calcoli effettuati dal business Tier siano corretti e appropriati
- Database Tier : si occupa di gestire i dati all'interno di archivi (in alcuni casi si parla anche di Legacy Data Storage Tier per archivi che non sono database)
Architettura a un livello
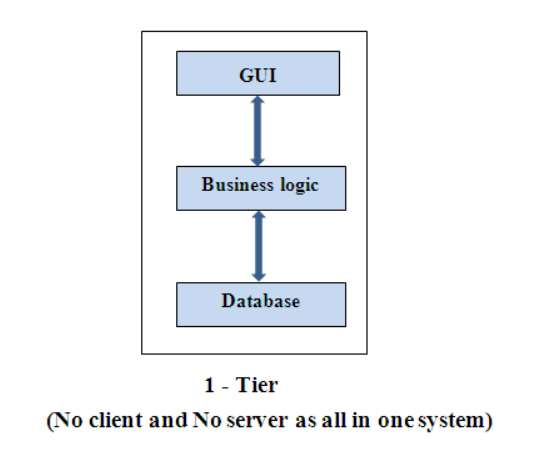
tutto l'applicativo gira sullo stesso PC
Archiettura a 2 Tier
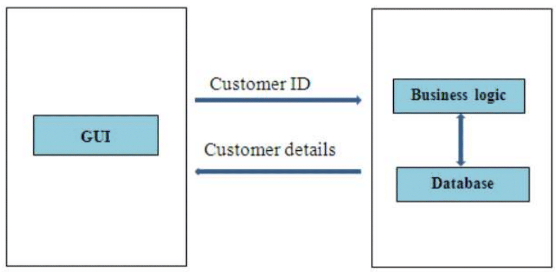
l'applicativo gira in un PC, mentre il resto (elaborazione e archiviazione su un altro sistema)
Architettura a tre livelli

La presentazione, l’elaborazione applicativa e la gestione dei dati sono processi logicamente separati ed eseguiti su processori diversi
Esempio: Un sistema di internet banking:
- il database dei clienti, mainframe fornisce i servizi di gestione dei dati
- un server web fornisce i servizi applicativi estratti conto, invio di pagamenti, ecc.
- il computer dell’utente, dotato di un browser internet è il client
Thin e Tick client
Se il client si occupa solamente di visualizzare pagine senza avere una elaborazione (cioè che Tutte le elaborazioni applicative e la gestione dei dati sono gestite dal server) si dice Thin Client, se invece esegue un minimo di elaborazione dei dati si dice Tick Client.
Thin client
Vantaggi:
Tutte le elaborazioni applicative e la gestione dei dati sono gestite dal server.
Il client si occupa soltanto di eseguire il software di presentazione
Svantaggi:
- Pesante carico di lavoro sul server e sulla rete
- La potenza di elaborazione dei dispositivi client viene sprecata
Thick client
Vantaggi:
- Il server è responsabile della gestione dei dati
- Il client è responsabile di presentazione e logica applicativa (aumentata potenza di calcolo dei PC)
Svantaggi:
La gestione del sistema è più complessa
Le funzionalità dell’applicazione sono divise su diversi computer
Quando deve essere modificato il software è necessario reinstallare su ogni computer client
Costi notevoli
Architetture a oggetti distribuiti
Si intende una architettura dove esistono tanti sistemi che appartengo allo stesso Tier, ma che fanno azioni diverse (uno che si occupa di lavorare i dati relativi agli utenti, un altro i dati relativi agli animali domestici degli utenti, un altro i dati delle case degli utenti, …). I sistemi normalmente organizzati in questo modo sono fatti per elaborare i Big Data e/o fare Data Mining. Questa tecnica viene associata all'idea di cluster computing
Architetture peer-to-peer
Sono architetture utilizzate da applicazioni di file sharing (tipo Emule/uTorrent, l'instant Messaging, …)
