Gestione fisica degli archivi
Ricordiamo che un archivio ha 4 importanti azioni da fare:
- Inserimento: a seconda delle politiche dell’archivio ricerco per evitare duplicati e/o inserisco l’elemento in coda e/o in maniera ordinata. A seconda delle politiche il costo computazionale per inserire il dato varia.
- Ricerca: a seconda delle politiche dell’archivio posso effettuale una ricerca binaria e/o sequenziale. A seconda delle politiche il costo computazionale per la ricerca del dato varia.
- Modifica: trovo il dato da modificare e a seconda delle politiche dell’archivio eseguo la modifica riscrivendo il dato, cancellando e reinserendo un’altro, … A seconda delle politiche il costo computazionale per la modifica del dato varia.
- Eliminazione: trovo il dato da eliminare e a seconda delle politiche dell’archivio eseguo la cancellazione fisica e/o logica.
- La cancellazione fisica prevede l’eliminazione del record dal database.
- La cancellazione logica prevede di nascondere il record dal database tramite un flag o altro. è meno onerosa della cancellazione fisica. Inoltre permette il recupero dei dati. A seconda delle politiche il costo computazionale per la modifica del dato varia. Spesso in caso di cancellazione logica dopo un tot tempo viene fatta una pulizia dei record cancellati. La cancellazione può provocare inconsistenza.
Gli archivi devono permettere l’uso delle operazioni più frequenti in maniera veloce. Per questo non esiste solo un modo per gestire l’archivio, ma ne esistono tanti:
Gli archivi possono essere gestiti in numerosi modi:
Con accesso sequenziale: ciò indica che i dati occupano una dimensione variabile con delimitatori/separatori o campo lunghezza → posso accedere ai dati solo in sequenza;

L’accesso con questo sistema è oneroso e lento in quanto devo leggere dato per dato alla ricerca di eventuali campi lunghezze e/o delimitatori. Eliminazione e modifica lenta e onerosa.
Con accesso diretto/casuale: ciò indica che i dati occupano sempre la stessa dimensione → posso accedere ai dati come mi pare piace, posso eseguire la ricerca binaria se l’archivio è ordinato, inoltre è possibile gestire il file anche tramite alberi binari (o strutture similari) per una più veloce ricerca e inserimento;

Eliminazione e modifica lenta e onerosa. La differenza tra i due tipi di accesso si vede in questo schema:
L’accesso con questo sistema è generalmente più veloce e posso leggere anche metà di un dato e saltarlo se non mi è utile, non permette di utilizzare dati a lunghezza variabile.
Per ottimizzare le operazioni di inserimento e ricerca ordinata è possibile ottimizzare l’accesso casuale con l’uso di alberi binari o altre strutture simili (B-tree, red&black tree, …) all'interno del file. Grazie a questa tecnica le operazioni di inserimento, modifica e rimozione sono notevolmente ottimizzate.
Con accesso calcolato basato su due archivi distinti, esso può avere i blocchi a lunghezza fissa o variabile e può essere gestito tramite una funzione hash con gestione delle collisioni (solo se a lunghezza fissa), e/o un “sommario” (anche a lunghezza variabile) → posso accedere ai dati come mi pare piace;


L’utilizzo dei due metodi “tradizionale”: l’accesso diretto e sequenziale come si nota ha numerosi problemi, quindi sono stati ideati altri sistemi d’accesso:
- L’accesso tramite funzione hash ha dei vantaggi e svantaggi, è utile se come chiave univoca abbiamo un codice fiscale o un indirizzo IPv6 dove tante e tante combinazioni sono inutilizzate. Esso ha alcune caratteristiche:
- Da ogni chiave si genera un indirizzo costante;
- è semplice, veloce e poco onoreoso;
- Vengono usati tutti gli indirizzi in quanto il codominio della funzione hash comprende tutti gli indirizzi;
- Gli indirizzi calcolati coprono lo spazio in modo armonico;
- Però non è richiesto che due chiavi generino due indirizzi diversi e quindi bisogna sempre gestite questo caso: tramite alcuni algoritmi:
- scansione lineare (+1, +2, +3, …): aumentano i tempi di ricerca in quanto si ritorna ad una organizzazione sequenziale, occupando spazi anche di altre hash e realizzando un cluster (un ammasso) di dati.
- scansione quadratica (+1,+4,+9, …): aumentano i tempi di ricerca in quanto si ritorna ad una organizzazione ad accesso casuale, occupando spazi anche di altre hash.
- area di overlow: richiede un file separato, anche esso deve essere in qualche modo organizzato per una veloce lettura, è sconsigliato l’utilizzo di un’altra organizzazione hash. I primi due algoritmi garantiscono di generare un certo numero di nuove posizioni ma nessuno dei due riesce a nuove posizioni per tutti i dati, quindi spesso bisogna optare per un secondo archivio di overlow, gestito
- L’hash ha un buon uso dello spazio e una buona velocità;
- Non ha nessuna sequenza;
- L’acesso tramite chiave/puntatore utilizza un’idea simile all’hash ma assomiglia di più al sommario di un libro:
- Posso eliminare logicamente i blocchi eliminando il puntatore senza eliminare i dati;
- Supporto di dati a dimensione variabile;
- Operazione di inserimento e ricerca poco onerosa;
- Operazione di modifica poco onerosa se il nuovo spazio occupato è minore o uguale a quello vecchio, altrimenti bisogna gestirlo in qualche modo;
- Possibilità di rigenerare l’indice;
- La gestione delle chiavi/puntatore è possibile ottimizzarla tramite un’albero binario o altre strutture simili (B-tree, red&black tree, …)
- L’accesso tramite funzione hash ha dei vantaggi e svantaggi, è utile se come chiave univoca abbiamo un codice fiscale o un indirizzo IPv6 dove tante e tante combinazioni sono inutilizzate. Esso ha alcune caratteristiche:

Alberi di ricerca
L’utilizzo di alberi di ricerca è molto utile per la ricerca degli elementi e permette anche un’inserimento ordinato veloce. Come si vede da questa GIF in un albero creato in maniera non ordinata la ricerca è molto più veloce rispetto ad una organizzazione sequenziale, tipo l’array.
Ricerca nel BST (Binary Search Tree - Albero binario di ricerca)

L’utilizzo di questa struttura dati ha dei lati negativi, del tipo che l’inserimento non ha una politica di auto bilanciamento dell’albero e possono succedere casi del genere:
![]()
Che degradano le prestazioni della ricerca. La ricerca non è degradata se la differenza se per ogni nodo la differenza di tra il sotto albero di sinistra e quello di destra è al massimo di 1. Proprio per questo ci sono alcune tecniche per evitare ciò: gli alberi auto bilanciati. L’esempio più pratico sono i B-tree:
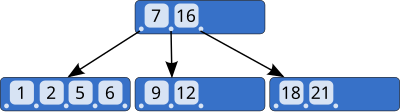
Nei B-tree c’è l’auto bilanciamento in fase di inserimento, le foglie sono sempre tutte allo stesso livello e l’inserimento si propaga verso l’alto.
Struttura di un nodo di B-Albero di grado N
- Un array di 2*N+1 puntatori a nodi
- Un array di 2*N dati (+1 eventualmente per lo sdoppiamento)
Caratteristiche di un nodo di B-Albero di grado N
- Tutte le foglie hanno la stessa profondità (l'albero è completamente bilanciato)
- Il numero di chiavi per nodo è limitato superiormente ed inferiormente. N>=2 è il grado minimo dell'albero
- Ogni nodo contiene almeno N-1 chiavi
- Ogni nodo contiene al massimo 2T-1 chiavi
- Tutte le foglie sono allo stesso livello
- L’inserimento avviene nelle foglie ma si può propagare verso l’alto
- L’inserimento e l’estrazione mantengono l’albero bilanciato
- Gli elementi sono ordinati
- Esiste la stampa simmetrica dell’albero
Però i B-tree sono una struttura dati complessa e alcune operazioni sono onerose per questo sono state ideate altri alberi, per esempio gli alberi red&black.
